Awhile back (still on WR I believe) we had a statistical break down of Wikipedia articles. If I remember correctly, of the 4 million+ or so, about 60% were stubs, another 10% were disambig pages and lists, which left only 30% or so (I'm repeating this stats from memory, so correct if I'm wrong, but I'm pretty sure this is in the ball park) as potentially legitimate articles.
The thing is, that once you venture outside of the more prominent topics, particularly outside of Europe/US/Australia etc topics, the articles there, putting aside frequent POV problems etc, are usually straight up copy-paste copyvios. Nobody notices because most of the most active Wikipedians hardly ever venture into those areas so they never make it to copyright investigations or related pages. For certain reasons I dip my toes into those waters occasionally and pretty much every time, I immediately stumble upon a copy paste.
Here's one:
University of Dhaka (T-H-L)
which is a copy-paste of (copyrighted) the University website http://www.du.ac.bd/theuniversity.php
I could fix it, but honestly, at this point, it's like spitting into an ocean.
Incidentally the reason I noticed this one is because of some wacky monkey business over at the Tangail (T-H-L) article (a district of Bangladesh) where some anon ip is trying to put in some obvious hoax-y stuff - best as I can make out he's putting in himself and his friends as "notable people", superpowers, side-kicks and all. Of course had I not reverted him/her, this stuff would be in there with no one the wiser. And that's basically a good chunk of Wikipedia.
So, out of those 30% (and that's a conservative estimate) non-stub, non-list, articles, what percentage is like University of Dhaka and Tangail? What % of those 4,120,818 can actually be called "legitimate" in even a weak sense of that word? 10%? 5%? 1%? Regardless, having that number up there on the main page is pretty obvious false advertising.
4,120,818 stubs, lists, disambig pages and ... copyvios
-
Volunteer Marek
- Habitué
- Posts: 1383
- kołdry
- Joined: Sun Mar 18, 2012 3:16 am
- Wikipedia User: Volunteer Marek
-
EricBarbour
- Posts: 10891
- Joined: Wed Mar 14, 2012 11:32 pm
- Location: hell
-
EricBarbour
- Posts: 10891
- Joined: Wed Mar 14, 2012 11:32 pm
- Location: hell
Re: 4,120,818 stubs, lists, disambig pages and ... copyvios
Plus, we discussed Indian and Bengali article subjects on WR last year. Said articles tend to be, to put it charitably,
biased and weird. And this is only what we see on en-WP. I can only imagine the madness posted on the Hindu, Gujarati,
Tamil, Bengali etc. wikis.
A few examples from en-wiki, all previously posted on WR:
http://en.wikipedia.org/wiki/Arta_%28Kamuia%29
http://en.wikipedia.org/wiki/Azhagappapuram
http://en.wikipedia.org/wiki/Doti (used to be a LOT worse)
http://en.wikipedia.org/wiki/Gangadhar_Pradhan
http://en.wikipedia.org/wiki/Mathews_Ma ... tropolitan
http://en.wikipedia.org/wiki/Mausala_Parva
A really primo bit of Muslim Wiki-slobber:
http://en.wikipedia.org/wiki/Baha-ud-Di ... nd_Bukhari
I'm not worried about Seren or some other nut fixing these, because en-wiki has thousands of them.
biased and weird. And this is only what we see on en-WP. I can only imagine the madness posted on the Hindu, Gujarati,
Tamil, Bengali etc. wikis.
A few examples from en-wiki, all previously posted on WR:
http://en.wikipedia.org/wiki/Arta_%28Kamuia%29
http://en.wikipedia.org/wiki/Azhagappapuram
http://en.wikipedia.org/wiki/Doti (used to be a LOT worse)
http://en.wikipedia.org/wiki/Gangadhar_Pradhan
http://en.wikipedia.org/wiki/Mathews_Ma ... tropolitan
http://en.wikipedia.org/wiki/Mausala_Parva
A really primo bit of Muslim Wiki-slobber:
http://en.wikipedia.org/wiki/Baha-ud-Di ... nd_Bukhari
I'm not worried about Seren or some other nut fixing these, because en-wiki has thousands of them.
-
Randy from Boise

- Been Around Forever
- Posts: 12227
- Joined: Sun Mar 18, 2012 2:32 am
- Wikipedia User: Carrite
- Wikipedia Review Member: Timbo
- Actual Name: Tim Davenport
- Nom de plume: T. Chandler
- Location: Boise, Idaho
Re: 4,120,818 stubs, lists, disambig pages and ... copyvios
I don't accept that 10k is the magic breakpoint between stubbishness and fulsomeness. Something more like 5k is probably closer to the mark, which would easily double the count of "useful" articles.EricBarbour wrote:
Even if it's 2/3 dreck, there would be over a million relevant articles. It's a big mama even allowing for flab and fluff.
We see metrics about declining numbers of casual editors, stagnant numbers of very active editors, and declining numbers of administrators. What about the output of new articles? It doesn't seem like the new articles queue is drying up, by any stretch of the imagination — things went from 4 million to 4.1 million in the blink of an eye. The number I'd like to see is monthly net increase in articles.
That said, visiting the new articles queue shows lots of puffy fluff about athletes (of whom there are a limitless supply), small time authors, and minor politicians. Not a great deal of writing about "serious" topics, in other words. So there may well be a quantitative content crisis which would not be measured by a raw count of the increase in size.
I'm still quite bullish on Wikipedia as an educational resource, systemic flaws and all.
RfB
-
Randy from Boise
- Been Around Forever
- Posts: 12227
- Joined: Sun Mar 18, 2012 2:32 am
- Wikipedia User: Carrite
- Wikipedia Review Member: Timbo
- Actual Name: Tim Davenport
- Nom de plume: T. Chandler
- Location: Boise, Idaho
Re: 4,120,818 stubs, lists, disambig pages and ... copyvios
To make my point, here's the first 5K-ish article I bumped into with the Random Article button... (Third pull of the lever, after a disambiguation page and a stub.)
http://en.wikipedia.org/wiki/Traffic_Signal_(film)
I think we all could agree that there is enough meat there that it would be useful to someone running a search for it...
And that has been accessed 4,552 times in the last month, so it is being sought and found by real world users...
RfB
http://en.wikipedia.org/wiki/Traffic_Signal_(film)
I think we all could agree that there is enough meat there that it would be useful to someone running a search for it...
And that has been accessed 4,552 times in the last month, so it is being sought and found by real world users...
RfB
-
The Devil's Advocate

- Habitué
- Posts: 1908
- Joined: Thu Jun 14, 2012 12:19 am
- Wikipedia User: The Devil's Advocate
Re: 4,120,818 stubs, lists, disambig pages and ... copyvios
Nearly all of the "meat" of that article is plot summary and thus is not really educational in any meaningful sense. You are correct in the premise that 10k is probably not the bar that should be used as an article consisting of three sourced paragraphs about some obscure 16th century noble can be pretty educational even when the article isn't that large. However, that article is not the example I would use to make such a point.Randy from Boise wrote:To make my point, here's the first 5K-ish article I bumped into with the Random Article button... (Third pull of the lever, after a disambiguation page and a stub.)
http://en.wikipedia.org/wiki/Traffic_Signal_(film)
I think we all could agree that there is enough meat there that it would be useful to someone running a search for it...
And that has been accessed 4,552 times in the last month, so it is being sought and found by real world users...
RfB
"For those who stubbornly seek freedom around the world, there can be no more urgent task than to come to understand the mechanisms and practices of indoctrination."
- Noam Chomsky
-
Randy from Boise
- Been Around Forever
- Posts: 12227
- Joined: Sun Mar 18, 2012 2:32 am
- Wikipedia User: Carrite
- Wikipedia Review Member: Timbo
- Actual Name: Tim Davenport
- Nom de plume: T. Chandler
- Location: Boise, Idaho
Re: 4,120,818 stubs, lists, disambig pages and ... copyvios
No, not educational. Wikipedia is both an encyclopedia and a compendium of popular culture and the random article I linked up is decidedly in the latter category. But 5k is enough substance to give those who seek what they have come to find, in most cases. That should be the benchmark between a stub and a substantial piece, not 10k, is my point...The Devil's Advocate wrote:Nearly all of the "meat" of that article is plot summary and thus is not really educational in any meaningful sense. You are correct in the premise that 10k is probably not the bar that should be used as an article consisting of three sourced paragraphs about some obscure 16th century noble can be pretty educational even when the article isn't that large. However, that article is not the example I would use to make such a point.Randy from Boise wrote:To make my point, here's the first 5K-ish article I bumped into with the Random Article button... (Third pull of the lever, after a disambiguation page and a stub.)
http://en.wikipedia.org/wiki/Traffic_Signal_(film)
I think we all could agree that there is enough meat there that it would be useful to someone running a search for it...
And that has been accessed 4,552 times in the last month, so it is being sought and found by real world users...
RfB
RfB
-
Randy from Boise
- Been Around Forever
- Posts: 12227
- Joined: Sun Mar 18, 2012 2:32 am
- Wikipedia User: Carrite
- Wikipedia Review Member: Timbo
- Actual Name: Tim Davenport
- Nom de plume: T. Chandler
- Location: Boise, Idaho
Re: 4,120,818 stubs, lists, disambig pages and ... copyvios
I punched the Random Article button 100 times and here's what I came up with:
Disambiguation Pages: 12%
Very Short Articles (<5K): 51%
Substantial Articles (5-10K): 21%
Very Long Articles (over 10K): 12%
Lists: 4%
That'd be 33% "beefy content," which was precisely my wild guess above.
========
The very short pieces tended to relate to geography (small towns, etc.) or science (insect species, etc.) and generally weren't completely worthless.
One of the "very long articles" was a porn bio, which was.
There were quite a few athletes, results of athletic competitions, and a couple on election returns, which is vaguely similar. Lots of movies, records, songs, books... Wikipedia is very strong for pop culture stuff... That's most of what ya see in the New Articles queue.
There was only one piece on pure math and only a fairly small number of serious social sciencey pieces. A couple decent historical biographies...
RfB
Disambiguation Pages: 12%
Very Short Articles (<5K): 51%
Substantial Articles (5-10K): 21%
Very Long Articles (over 10K): 12%
Lists: 4%
That'd be 33% "beefy content," which was precisely my wild guess above.
========
The very short pieces tended to relate to geography (small towns, etc.) or science (insect species, etc.) and generally weren't completely worthless.
One of the "very long articles" was a porn bio, which was.
There were quite a few athletes, results of athletic competitions, and a couple on election returns, which is vaguely similar. Lots of movies, records, songs, books... Wikipedia is very strong for pop culture stuff... That's most of what ya see in the New Articles queue.
There was only one piece on pure math and only a fairly small number of serious social sciencey pieces. A couple decent historical biographies...
RfB
-
Peter Damian

- Habitué
- Posts: 4206
- Joined: Thu Mar 15, 2012 8:14 pm
- Wikipedia User: Peter Damian
- Wikipedia Review Member: Peter Damian
- Location: London
- Contact:
Re: 4,120,818 stubs, lists, disambig pages and ... copyvios
Already drifted from the topic, namely that once you are off the beaten track, it is mostly copyvios. Close to a topic of one of the book chapters 'Robots' dealing with how the rapid growth of Wikipedia was fuelled by such copying. Wikipedia is mostly an aggregation engine of other stuff on the net. There is no magic crowdsourcing to the wiki. It's mainly plagiarism of this kind, plus a small amount of people like Randy adding their stuff, to no thanks whatever.
οὐκ ἀγαθὸν πολυκοιρανίη: εἷς κοίρανος ἔστω
-
Willbeheard

- Retired
- Posts: 271
- Joined: Mon Apr 30, 2012 9:49 pm
- Wikipedia User: Arniep
- Wikipedia Review Member: jorge
Re: 4,120,818 stubs, lists, disambig pages and ... copyvios
Certainly 10k is quite a high threshold. Looking through a biographical dictionary, I'd estimate that many of the articles there are around 2k, but tell you all you need to know about someone fairly obscure. To puff them up to say 12k, even if it can be done, you'd be filling them with trivia.
Copyvios are another issue, and there's no doubt about those. It would be an interesting exercise to compare a biographical dictionary with a few biographical articles.
Copyvios are another issue, and there's no doubt about those. It would be an interesting exercise to compare a biographical dictionary with a few biographical articles.
-
rd232
- Retired
- Posts: 209
- Joined: Sun Mar 18, 2012 8:46 pm
- Wikipedia User: rd232
- Wikipedia Review Member: rd232
Re: 4,120,818 stubs, lists, disambig pages and ... copyvios
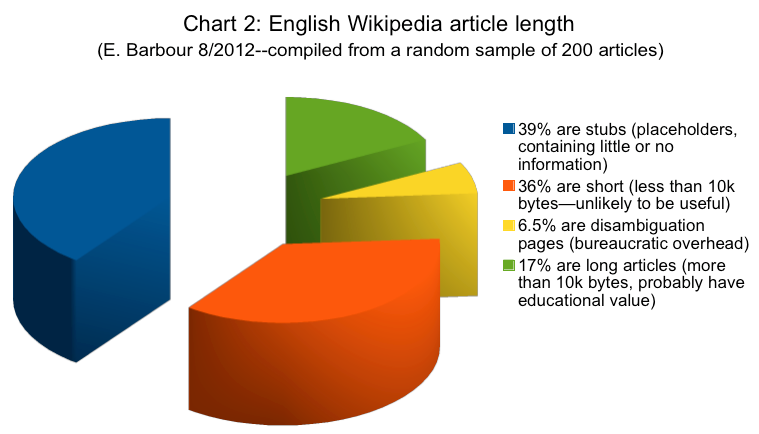
"stubs (placeholders containing little or no information)" - huh? On an obscure topic, a well-sourced stub of a couple of paragraphs can be gold. Substubs that are little more than "this thing exists" do happen, especially for places, and those are usually pointless - but even these can have value if they provide alternative names or alternative spellings of names.
Similarly, dismissing disambiguation pages as mere "bureaucratic overhead" misses the point that in the real world people actually need to distinguish (say) people of the same name, and disambiguation pages can be very helpful as pointers on doing that, even if the pages about the people are stubs. Obviously you wouldn't want to rely on such a page alone, but it can be very helpful for clues to follow up to good sources.
Similarly, dismissing disambiguation pages as mere "bureaucratic overhead" misses the point that in the real world people actually need to distinguish (say) people of the same name, and disambiguation pages can be very helpful as pointers on doing that, even if the pages about the people are stubs. Obviously you wouldn't want to rely on such a page alone, but it can be very helpful for clues to follow up to good sources.
Yes Wikimedia/Wikipedia/Commons (delete as appropriate) has problems. No, if I don't agree with you 100% on the nature, causes and extent of those problems, that doesn't mean I'm denying the existence of those problems.
-
lilburne

- Habitué
- Posts: 4446
- Joined: Thu Mar 15, 2012 6:18 pm
- Wikipedia User: Nastytroll
- Wikipedia Review Member: Lilburne
Re: 4,120,818 stubs, lists, disambig pages and ... copyvios
rd232 wrote:"stubs (placeholders containing little or no information)" - huh? On an obscure topic, a well-sourced stub of a couple of paragraphs can be gold. Substubs that are little more than "this thing exists" do happen, especially for places, and those are usually pointless - but even these can have value if they provide alternative names or alternative spellings of names.
Similarly, dismissing disambiguation pages as mere "bureaucratic overhead" misses the point that in the real world people actually need to distinguish (say) people of the same name, and disambiguation pages can be very helpful as pointers on doing that, even if the pages about the people are stubs. Obviously you wouldn't want to rely on such a page alone, but it can be very helpful for clues to follow up to good sources.
The issue here is that WP commonly boasts about 4,000,000+ articles. The reality is somewhat different, when half a million of those pages are disambiguation pages. WP will never be able to compete in quality with a site like Encyclopaedia of Life. The reason being that one really can't trust the information on the WP pages that aren't just rips from a species list database. As for the history, well that is all over the place on WP, they regularly link a name in one article to someone that is of a different generation, or even a different century. And lets ignore the mess that redirects introduce.
They have been inserting little memes in everybody's mind
So Google's shills can shriek there whenever they're inclined
So Google's shills can shriek there whenever they're inclined
-
Randy from Boise
- Been Around Forever
- Posts: 12227
- Joined: Sun Mar 18, 2012 2:32 am
- Wikipedia User: Carrite
- Wikipedia Review Member: Timbo
- Actual Name: Tim Davenport
- Nom de plume: T. Chandler
- Location: Boise, Idaho
Re: 4,120,818 stubs, lists, disambig pages and ... copyvios
There are two only loosely related issues in this thread, both important.lilburne wrote:
The issue here is that WP commonly boasts about 4,000,000+ articles. The reality is somewhat different, when half a million of those pages are disambiguation pages. WP will never be able to compete in quality with a site like Encyclopaedia of Life. The reason being that one really can't trust the information on the WP pages that aren't just rips from a species list database. As for the history, well that is all over the place on WP, they regularly link a name in one article to someone that is of a different generation, or even a different century. And lets ignore the mess that redirects introduce.
1. There is an objection that EnglishWikipedia represents itself as containing "4.1 million articles" and that this constitutes "false advertising."
Point taken. Wikipedia doesn't have that many substantive articles, by any stretch. I think that a safe guess is that there are something in the order of 1.25 million substantive pieces and a couple million more fragmentary bits of lesser or greatly lesser value. The sum of these is uncountable, the 4.1 million figure is. Regardless, it is a big number, far bigger than any other comparable resource.
I will add that it is a stretch calling WP an encyclopedia. I like to refer to it as a "Serious Encyclopedia and Compendium of Popular Culture." Of these, the latter is much larger — perhaps by a factor of 3 or 4. The former is the one I care about myself.
2. There is a question of widely prevalent copyright violation.
I don't think anybody doubts that a big or even major percentage of the "couple million fragmentary bits" were mechanically generated from other internet sources. Most of these are later amended and expanded by humans. I don't think "copyright violation" adequately describes these pieces unless one is intent on delivering a rant rather than an analysis. "Perhaps one million article starts were made mechanically from other sources on the internet." That is true.
With respect to the 1.25 million or so beefier pieces, I don't think that "copyright violation" is in any way applicable on a meaningful scale. The days of copy-paste from the 1911 Encyclopedia Britannica are long, long, long gone. That started during the Sangerpedia period (or just after, that was such a brief moment and the article count was so small that it is difficult to say exactly) and ended, guessing here, circa 2005. Anybody pulling this sort of stunt now would be panned.
Obviously, there are copyright violations to be found, but they are the exception not the rule, are taken seriously, and are dealt with harshly. There is no nudge-nudge-wink-wink like there is at Commons with Flickerwashed images.
I think it is fair to say that stuff emanating from India is more problematic in terms of copyright than stuff coming from the UK, USA, Germany, or Australia. Presumably this will change over time as new editors from there learn acceptable standards and practices.
RfB
-
rd232
- Retired
- Posts: 209
- Joined: Sun Mar 18, 2012 8:46 pm
- Wikipedia User: rd232
- Wikipedia Review Member: rd232
Re: 4,120,818 stubs, lists, disambig pages and ... copyvios
Well that's true - it puts the number of mainspace pages on the front page as "articles" (currently 4.1m+), when in fact disambiguation pages are not considered articles. This is more a practical issue than anything else I think - the system doesn't easily strip out disambiguation pages from the statistics. But really, who (as a non-Wikipedian) cares about whether the article total is 0.1m, 1m, 10m?lilburne wrote:The issue here is that WP commonly boasts about 4,000,000+ articles. The reality is somewhat different, when half a million of those pages are disambiguation pages.
quality of that sort is the real issue, but really that's a matter for another thread (well, many other threads).lilburne wrote:WP will never be able to compete in quality with a site like Encyclopaedia of Life. The reason being that one really can't trust the information on the WP pages that aren't just rips from a species list database. As for the history, well that is all over the place on WP, they regularly link a name in one article to someone that is of a different generation, or even a different century. And lets ignore the mess that redirects introduce.
Yes Wikimedia/Wikipedia/Commons (delete as appropriate) has problems. No, if I don't agree with you 100% on the nature, causes and extent of those problems, that doesn't mean I'm denying the existence of those problems.
-
Peter Damian
- Habitué
- Posts: 4206
- Joined: Thu Mar 15, 2012 8:14 pm
- Wikipedia User: Peter Damian
- Wikipedia Review Member: Peter Damian
- Location: London
- Contact:
Re: 4,120,818 stubs, lists, disambig pages and ... copyvios
You keep saying this, and I keep saying that, yes, they are gone in the sense that all the 1911 articles have been copied over. In the sense that they are still there, mostly uncorrected, those days are not gone.Randy from Boise wrote:The days of copy-paste from the 1911 Encyclopedia Britannica are long, long, long gone. RfB
οὐκ ἀγαθὸν πολυκοιρανίη: εἷς κοίρανος ἔστω
-
lilburne
- Habitué
- Posts: 4446
- Joined: Thu Mar 15, 2012 6:18 pm
- Wikipedia User: Nastytroll
- Wikipedia Review Member: Lilburne
Re: 4,120,818 stubs, lists, disambig pages and ... copyvios
Yeah well that former bit says that one of my contemporaries John Lilburne (T-H-L) was a Marxist.Randy from Boise wrote:I like to refer to it as a "Serious Encyclopedia and Compendium of Popular Culture." Of these, the latter is much larger — perhaps by a factor of 3 or 4. The former is the one I care about myself.lilburne wrote:
The issue here is that WP commonly boasts about 4,000,000+ articles. The reality is somewhat different, when half a million of those pages are disambiguation pages. WP will never be able to compete in quality with a site like Encyclopaedia of Life. The reason being that one really can't trust the information on the WP pages that aren't just rips from a species list database. As for the history, well that is all over the place on WP, they regularly link a name in one article to someone that is of a different generation, or even a different century. And lets ignore the mess that redirects introduce.
RfB
They have been inserting little memes in everybody's mind
So Google's shills can shriek there whenever they're inclined
So Google's shills can shriek there whenever they're inclined
-
EricBarbour
- Posts: 10891
- Joined: Wed Mar 14, 2012 11:32 pm
- Location: hell
Re: 4,120,818 stubs, lists, disambig pages and ... copyvios
Choose some sports-related articles that contain a lot of statistics. Individual athletes or teams, and their win/lose and other figures.
Chances are excellent that most or all of those stats were copied from commercial websites such as Sports Reference.
Where they are copyright protected. There are even bots that do nothing but steal data from sports websites.
Chances are excellent that most or all of those stats were copied from commercial websites such as Sports Reference.
Where they are copyright protected. There are even bots that do nothing but steal data from sports websites.
-
Randy from Boise
- Been Around Forever
- Posts: 12227
- Joined: Sun Mar 18, 2012 2:32 am
- Wikipedia User: Carrite
- Wikipedia Review Member: Timbo
- Actual Name: Tim Davenport
- Nom de plume: T. Chandler
- Location: Boise, Idaho
Re: 4,120,818 stubs, lists, disambig pages and ... copyvios
This is an interesting question that probably deserves its own thread.EricBarbour wrote:Choose some sports-related articles that contain a lot of statistics. Individual athletes or teams, and their win/lose and other figures.
Chances are excellent that most or all of those stats were copied from commercial websites such as Sports Reference.
Where they are copyright protected. There are even bots that do nothing but steal data from sports websites.
Stats are stats at one level, like population totals or the number of people dying due to auto accidents or eating poisonous mushrooms. There are clearly some proprietary statistics on sports-reference.com — the NBA "per 36 minutes" numbers come to mind. But basic stats are basic stats and belong to nobody, in my view.
Sports-reference's numbers come from the various leagues in their original form.
RfB
-
TungstenCarbide

- Habitué
- Posts: 2592
- Joined: Thu Apr 05, 2012 1:51 am
- Wikipedia User: TungstenCarbide
- Wikipedia Review Member: TungstenCarbide
Re: 4,120,818 stubs, lists, disambig pages and ... copyvios
That's right, facts are not copyrightable. The way they are presented or chosen or formatted may be though.Randy from Boise wrote:This is an interesting question that probably deserves its own thread.EricBarbour wrote:Choose some sports-related articles that contain a lot of statistics. Individual athletes or teams, and their win/lose and other figures.
Chances are excellent that most or all of those stats were copied from commercial websites such as Sports Reference.
Where they are copyright protected. There are even bots that do nothing but steal data from sports websites.
Stats are stats at one level, like population totals or the number of people dying due to auto accidents or eating poisonous mushrooms. There are clearly some proprietary statistics on sports-reference.com — the NBA "per 36 minutes" numbers come to mind. But basic stats are basic stats and belong to nobody, in my view.
Sports-reference's numbers come from the various leagues in their original form.
RfB
Gone hiking. also, beware of women with crazy head gear and a dagger.
-
The Devil's Advocate
- Habitué
- Posts: 1908
- Joined: Thu Jun 14, 2012 12:19 am
- Wikipedia User: The Devil's Advocate
Re: 4,120,818 stubs, lists, disambig pages and ... copyvios
Strictly speaking, statistics cannot be copyrighted and this is backed up by numerous court rulings. No site can make a credible copyright claim over some athlete's RBI, for instance. I guess it depends on what you are thinking about when you talk about statistics in Wikipedia articles.EricBarbour wrote:Choose some sports-related articles that contain a lot of statistics. Individual athletes or teams, and their win/lose and other figures.
Chances are excellent that most or all of those stats were copied from commercial websites such as Sports Reference.
Where they are copyright protected. There are even bots that do nothing but steal data from sports websites.
"For those who stubbornly seek freedom around the world, there can be no more urgent task than to come to understand the mechanisms and practices of indoctrination."
- Noam Chomsky
-
rd232
- Retired
- Posts: 209
- Joined: Sun Mar 18, 2012 8:46 pm
- Wikipedia User: rd232
- Wikipedia Review Member: rd232
Re: 4,120,818 stubs, lists, disambig pages and ... copyvios
True - most copyright laws specifically exempt facts. But the European Union has Database right (T-H-L), which is a can of worms that (AFAIK) nobody knows what to do with on WP, so it's muchly ignored. (As a new legal concept, I don't think there's that much guidance or precedent, which doesn't help.)The Devil's Advocate wrote:Strictly speaking, statistics cannot be copyrighted and this is backed up by numerous court rulings. No site can make a credible copyright claim over some athlete's RBI, for instance. I guess it depends on what you are thinking about when you talk about statistics in Wikipedia articles.
Yes Wikimedia/Wikipedia/Commons (delete as appropriate) has problems. No, if I don't agree with you 100% on the nature, causes and extent of those problems, that doesn't mean I'm denying the existence of those problems.
-
EricBarbour
- Posts: 10891
- Joined: Wed Mar 14, 2012 11:32 pm
- Location: hell
Re: 4,120,818 stubs, lists, disambig pages and ... copyvios
Correct, although it bring up another question: what would a copyright attorney say about this, if he knew the scope of this automated "theft"?The Devil's Advocate wrote:Strictly speaking, statistics cannot be copyrighted and this is backed up by numerous court rulings. No site can make a credible copyright claim over some athlete's RBI, for instance. I guess it depends on what you are thinking about when you talk about statistics in Wikipedia articles.
At what point does "presentation" enter into the discussion? I've tried to tell the owners of Sports Reference that their site was being scraped by
Wikipedians heavily, and have not gotten any response.
-
Zagalejo

- Contributor
- Posts: 11
- Joined: Sat Sep 01, 2012 4:26 am
- Wikipedia User: Zagalejo
- Location: Chicago
Re: 4,120,818 stubs, lists, disambig pages and ... copyvios
Someone from one of the Sports-Reference sites once told me that they got their information from books like "Total Basketball". And those books were surely piggybacking off older sports encyclopedias. It's not like any of these people have been watching every game with scorecards since the 1940s.EricBarbour wrote:Correct, although it bring up another question: what would a copyright attorney say about this, if he knew the scope of this automated "theft"?The Devil's Advocate wrote:Strictly speaking, statistics cannot be copyrighted and this is backed up by numerous court rulings. No site can make a credible copyright claim over some athlete's RBI, for instance. I guess it depends on what you are thinking about when you talk about statistics in Wikipedia articles.
At what point does "presentation" enter into the discussion? I've tried to tell the owners of Sports Reference that their site was being scraped by
Wikipedians heavily, and have not gotten any response.
Also, Sports-Reference seems to have tolerated the existence of databasesports.com, which is largely the same content.
-
HRIP7

- Denizen
- Posts: 6953
- Joined: Thu Mar 15, 2012 2:05 am
- Wikipedia User: Jayen466
- Wikipedia Review Member: HRIP7
- Actual Name: Andreas Kolbe
- Location: UK
Re: 4,120,818 stubs, lists, disambig pages and ... copyvios
As it happens, the figures were just updated today. According to the latest figures, mainspace has 4172397 pages plus 5723506 redirects.rd232 wrote:Well that's true - it puts the number of mainspace pages on the front page as "articles" (currently 4.1m+), when in fact disambiguation pages are not considered articles. This is more a practical issue than anything else I think - the system doesn't easily strip out disambiguation pages from the statistics. But really, who (as a non-Wikipedian) cares about whether the article total is 0.1m, 1m, 10m?lilburne wrote:The issue here is that WP commonly boasts about 4,000,000+ articles. The reality is somewhat different, when half a million of those pages are disambiguation pages.
No. ID Name Non-redirects Redirects Total
1 0 (Main) 4172397 5723506 9895903
2 1 Talk 4330750 519477 4850227
3 2 User 1488788 109749 1598537
4 3 User talk 8338500 42335 8380835
5 4 Wikipedia 655257 98187 753444
6 5 Wikipedia talk 151126 42397 193523
7 6 File 817154 4262 821416
8 7 File talk 163204 980 164184
9 8 MediaWiki 1650 19 1669
10 9 MediaWiki talk 894 108 1002
11 10 Template 382241 88235 470476
12 11 Template talk 170090 21507 191597
13 12 Help 593 586 1179
14 13 Help talk 450 132 582
15 14 Category 942769 4 942773
16 15 Category talk 620828 256 621084
17 100 Portal 106456 8866 115322
18 101 Portal talk 27745 1193 28938
19 108 Book 3335 342 3677
20 109 Book talk 3307 191 3498
21 447 Education Program talk 1 0 1
22 710 TimedText 28 0 28
23 711 TimedText talk 21 0 21
Totals 22377584 6662332 29039916
-
Hex
- Retired
- Posts: 4130
- Joined: Thu Nov 01, 2012 1:40 pm
- Wikipedia User: Scott
- Location: London
- Contact:
Re: 4,120,818 stubs, lists, disambig pages and ... copyvios
Everything that he said.rd232 wrote:"stubs (placeholders containing little or no information)" - huh? On an obscure topic, a well-sourced stub of a couple of paragraphs can be gold. Substubs that are little more than "this thing exists" do happen, especially for places, and those are usually pointless - but even these can have value if they provide alternative names or alternative spellings of names.
Similarly, dismissing disambiguation pages as mere "bureaucratic overhead" misses the point that in the real world people actually need to distinguish (say) people of the same name, and disambiguation pages can be very helpful as pointers on doing that, even if the pages about the people are stubs. Obviously you wouldn't want to rely on such a page alone, but it can be very helpful for clues to follow up to good sources.
At the time of posting there are 223,187 disambiguation pages. (See here.)lilburne wrote:half a million of those pages are disambiguation pages.
My question, to this esteemed Wiki community, is this: Do you think that a Wiki could successfully generate a useful encyclopedia? -- JimboWales
Yes, but in the end it wouldn't be an encyclopedia. It would be a wiki. -- WardCunningham (Jan 2001)
Yes, but in the end it wouldn't be an encyclopedia. It would be a wiki. -- WardCunningham (Jan 2001)
-
rd232
- Retired
- Posts: 209
- Joined: Sun Mar 18, 2012 8:46 pm
- Wikipedia User: rd232
- Wikipedia Review Member: rd232
Re: 4,120,818 stubs, lists, disambig pages and ... copyvios
Nearly right - that category includes disambiguation pages in all namespaces. Good idea though, and it means we can autocalculate the correct total (well *more* correct - depends on the accuracy of the category membership). Hence cat, meet pigeons.Hex wrote:At the time of posting there are 223,187 disambiguation pages. (See here.)
Yes Wikimedia/Wikipedia/Commons (delete as appropriate) has problems. No, if I don't agree with you 100% on the nature, causes and extent of those problems, that doesn't mean I'm denying the existence of those problems.
-
Hex
- Retired
- Posts: 4130
- Joined: Thu Nov 01, 2012 1:40 pm
- Wikipedia User: Scott
- Location: London
- Contact:
Re: 4,120,818 stubs, lists, disambig pages and ... copyvios
Good catch.rd232 wrote:Nearly right - that category includes disambiguation pages in all namespaces.
Beat you to it with the idea - see the technical pump.
My question, to this esteemed Wiki community, is this: Do you think that a Wiki could successfully generate a useful encyclopedia? -- JimboWales
Yes, but in the end it wouldn't be an encyclopedia. It would be a wiki. -- WardCunningham (Jan 2001)
Yes, but in the end it wouldn't be an encyclopedia. It would be a wiki. -- WardCunningham (Jan 2001)
-
Willbeheard
- Retired
- Posts: 271
- Joined: Mon Apr 30, 2012 9:49 pm
- Wikipedia User: Arniep
- Wikipedia Review Member: jorge
Re: 4,120,818 stubs, lists, disambig pages and ... copyvios
There is a project to copy over the whole Dictionary of National Biography. Charles Matthews is very keen on it, he told me once. He is assembling it on Wikisource for just that purpose.Peter Damian wrote:You keep saying this, and I keep saying that, yes, they are gone in the sense that all the 1911 articles have been copied over. In the sense that they are still there, mostly uncorrected, those days are not gone.Randy from Boise wrote:The days of copy-paste from the 1911 Encyclopedia Britannica are long, long, long gone. RfB
http://en.wikisource.org/wiki/Wikisourc ... roject_DNB